Hello friends! we have come with another useful topic as usual, OK have you heard about DeepRacer? 🤔🤔🤔 Don't worry if you haven't yet. Today we will go through the DeepRacer event with a past result deeply. DeepRacer is a tool created by Amazon AWS to learn machine learning (ML) easily. They use a special learning type called Reinforcement Learning. We can build applications for vehicles for autonomous driving in both virtual and physical environments. All the information is there in the AWS DeepRacer Developer Guide. Here we are going to share our experiences we have got in the training period and the virtual race day, they may be good or bad but will be beneficial for future racers.
AWS DeepRacer League


Make your car
What we need to do at first in the console, we need to have an agent. Here it is a 1/18th scaled car. In the Your garage section, all cars that are already built are listed and it also provides a button to create new cars as well.

If we click the button it will ask for all the specifications, action space, and personalization. Here DeepRacer team will recommend selecting the radio button Camera only in Sensor modification.




Make you model


Reward functions
1] Time trial - follow the center line (Default)
def reward_function(params): ''' Example of rewarding the agent to follow center line ''' # Read input parameters track_width = params['track_width'] distance_from_center = params['distance_from_center'] # Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width # Give higher reward if the car is closer to center line and vice versa if distance_from_center <= marker_1: reward = 1.0 elif distance_from_center <= marker_2: reward = 0.5 elif distance_from_center <= marker_3: reward = 0.1 else: reward = 1e-3 # likely crashed/ close to off track return float(reward)
2] Time trial - stay inside the two borders
def reward_function(params): ''' Example of rewarding the agent to stay inside the two borders of the track ''' # Read input parameters all_wheels_on_track = params['all_wheels_on_track'] distance_from_center = params['distance_from_center'] track_width = params['track_width'] # Give a very low reward by default reward = 1e-3 # Give a high reward if no wheels go off the track and # the agent is somewhere in between the track borders if all_wheels_on_track and (0.5*track_width - distance_from_center) >= 0.05: reward = 1.0 # Always return a float value return float(reward)
3] Time trial - prevent zig-zag
def reward_function(params): ''' Example of penalize steering, which helps mitigate zig-zag behaviors ''' # Read input parameters distance_from_center = params['distance_from_center'] track_width = params['track_width'] steering = abs(params['steering_angle']) # Only need the absolute steering angle # Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width # Give higher reward if the agent is closer to center line and vice versa if distance_from_center <= marker_1: reward = 1 elif distance_from_center <= marker_2: reward = 0.5 elif distance_from_center <= marker_3: reward = 0.1 else: reward = 1e-3 # likely crashed/ close to off track # Steering penality threshold, change the number based on your action space setting ABS_STEERING_THRESHOLD = 15 # Penalize reward if the agent is steering too much if steering > ABS_STEERING_THRESHOLD: reward *= 0.8 return float(reward)
4] Object avoidance and head-to-head - stay on one lane and not crashing (default for OA and h2h)
def reward_function(params): ''' Example of rewarding the agent to stay inside two borders and penalizing getting too close to the objects in front ''' all_wheels_on_track = params['all_wheels_on_track'] distance_from_center = params['distance_from_center'] track_width = params['track_width'] objects_distance = params['objects_distance'] _, next_object_index = params['closest_objects'] objects_left_of_center = params['objects_left_of_center'] is_left_of_center = params['is_left_of_center'] # Initialize reward with a small number but not zero # because zero means off-track or crashed reward = 1e-3 # Reward if the agent stays inside the two borders of the track if all_wheels_on_track and (0.5 * track_width - distance_from_center) >= 0.05: reward_lane = 1.0 else: reward_lane = 1e-3 # Penalize if the agent is too close to the next object reward_avoid = 1.0 # Distance to the next object distance_closest_object = objects_distance[next_object_index] # Decide if the agent and the next object is on the same lane is_same_lane = objects_left_of_center[next_object_index] == is_left_of_center if is_same_lane: if 0.5 <= distance_closest_object < 0.8: reward_avoid *= 0.5 elif 0.3 <= distance_closest_object < 0.5: reward_avoid *= 0.2 elif distance_closest_object < 0.3: reward_avoid = 1e-3 # Likely crashed # Calculate reward by putting different weights on # the two aspects above reward += 1.0 * reward_lane + 4.0 * reward_avoid return reward
Function that we used in the traning before the race day (model M20)
import math def reward_function(params): progress = params['progress'] # Read input variables waypoints = params['waypoints'] closest_waypoints = params['closest_waypoints'] heading = params['heading'] reward = 1.0 if progress == 100: reward += 100 # Calculate the direction of the center line based on the closest waypoints next_point = waypoints[closest_waypoints[1]] prev_point = waypoints[closest_waypoints[0]] # Calculate the direction in radius, arctan2(dy, dx), the result is (-pi, pi) in radians track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0]) # Convert to degree track_direction = math.degrees(track_direction) # Calculate the difference between the track direction and the heading direction of the car direction_diff = abs(track_direction - heading) # Penalize the reward if the difference is too large DIRECTION_THRESHOLD = 10.0 malus=1 if direction_diff > DIRECTION_THRESHOLD: malus=1-(direction_diff/50) if malus<0 or malus>1: malus = 0 reward *= malus return reward
Function that we used in the race day (model M11)
import math def reward_function(params): ''' Use square root for center line - ApiDragons-M11 ''' track_width = params['track_width'] distance_from_center = params['distance_from_center'] speed = params['speed'] progress = params['progress'] all_wheels_on_track = params['all_wheels_on_track'] SPEED_TRESHOLD = 3 reward = 1 - (distance_from_center / (track_width/2))**(4) if reward < 0: reward = 0 if speed > SPEED_TRESHOLD: reward *= 0.8 if not (all_wheels_on_track): reward = 0 if progress == 100: reward += 100 return float(reward)
Model training and evaluation
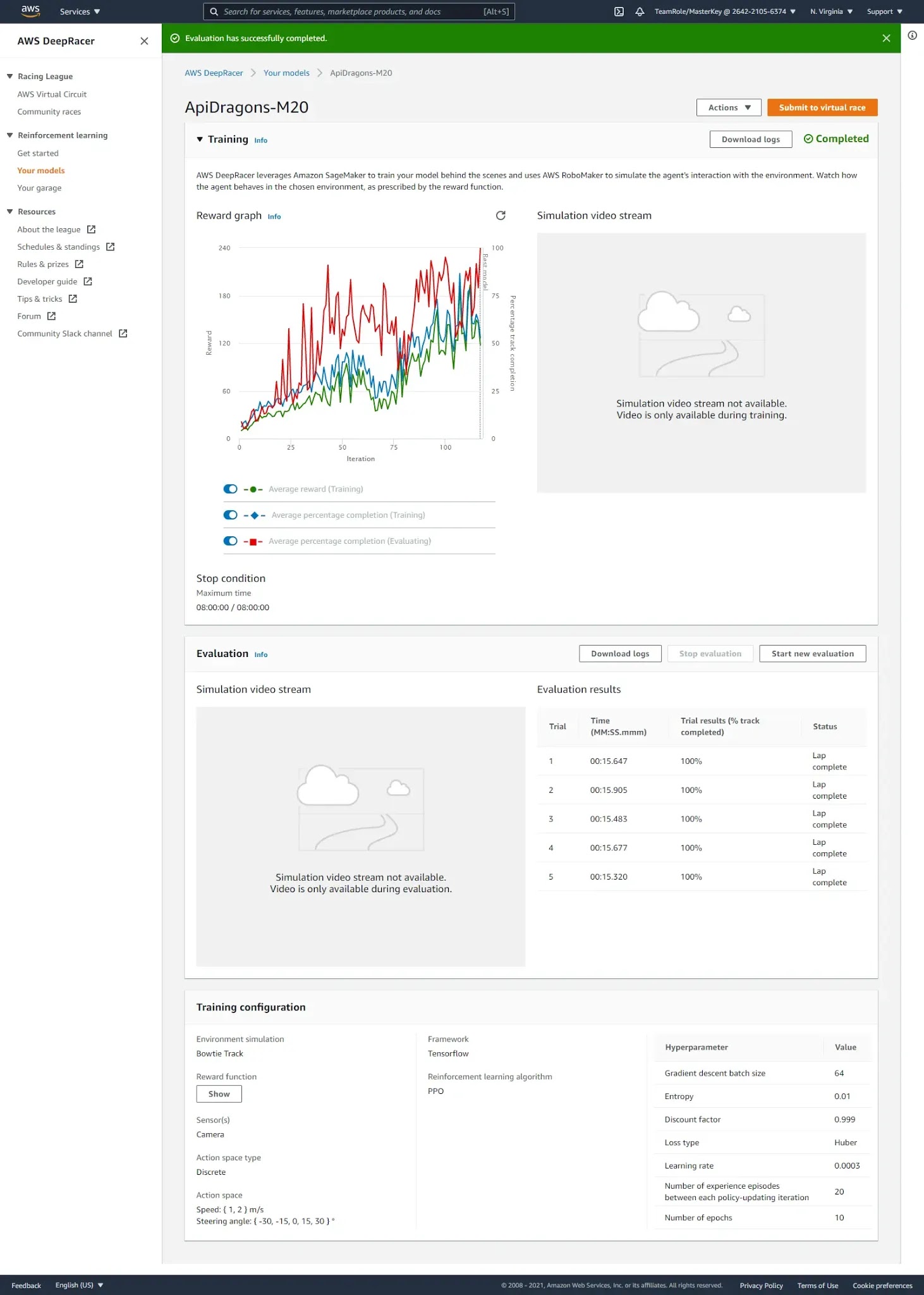



- We used 3m/s as the speed but we had to choose the max value, 4m/s for the action space.
- We had used a longer period of time like 8, 10 hours as the training time but it is enough to train 2 to 4 hour for better results.
- We did not trust default reward functions and always looked for a complex function but it is not correct, the results would be better if the reward function was a little bit simpler than that we have used.
- We had just concerned about the best lap time in the leader board before the race day so we had selected model M11 for the race day. but it was not much stable. If we went with model M20 which has already shown a 5 100% completed laps, the final results would rather be joyful though it did not have a better lap time. Because it was a stable model that M11.

Post a Comment